When your Fragment puts some actions in the action bar, it should call setHasOptionsMenu(true). And where should you make this call? You probably follow samples and call it from onCreate() callback.
Later you decide to hide one of the actions under certain circumstances. The way do to this is to implement onPrepareOptionsMenu(Menu) callback and alter the Menu object passed as an argument.
If you are not careful, depending on the visibility precondition you apply, you might have implemented instant crash on OS versions before Jelly Bean. On API level 17, the onPrepareOptionsMenu is called from runnable posted on some handler; on older versions the menu callbacks are called synchronously, so they are really called from onCreate(), which means that your Fragment is not yet fully initialized.
What’s the takeaway? Always test your app on wide variety of devices and OSes before the release, do not trust official Android samples, and call setHasOptionsMenu(true) at the end of onActivityCreated().
Today during the routine check of Android crash reports, I saw that one of the custom SQLite queries fails with ambiguous column: id message. There were two interesting aspects of this issue: nobody touched this part of code for a while; and there were only handful of crashes from a single device, and when you have a botched query it should crash left, right and center.
Fortunately a while back we decided to log the sqlite version available on a given device, so I had the crucial piece of information that let me find the root cause in no time. This particular device used custom ROM with Sqlite 3.8.x installed, which caught my eye, because the standard version used by Android 4.x is 3.7.11.
SQLite 3.7.11 assumes the user wants to group the rows by x.id, 3.8 fails with ambiguous column: id error, which is more sensible thing to do. The fix is trivial:
1
SELECT*FROMxLEFTJOINyONx.id=y.x_idGROUPBYx.id
What’s really important about this gotcha is that sqlite 3.8 will be the default version used by Android L, rumored to be released on November 1st. You might say that you don’t have any custom queries in your app, but you’d have to consider every dependency performing any data persistence you use. The best course of action is to test your application thoroughly on device with L preview image or emulator.
Some arguments are renamed, SQL-specific groupBy+having are omitted, and limit also got an axe, but it is pretty much the same, except for the first argument.
Content Uris 101
Instead of specifying database table, you have to pass the Uri describing the resource you want to access. By convention the Uri should have content scheme (use SCHEME_CONTENT constant), followed by the ContentProvider authority, and the path, which is mapped to resources.
If you have ever accessed any REST-ish API, or built the routes table for the web app, you’ll find it familiar. Querying /foo should return the list of foos, /foo/1 operates on foo with id 1 and /foo/1/bar refers to all bars related to foo with id 1. The last Uri pattern is not mentioned in API Guides, but is widely used in Google I/O Schedule app and system ContentProviders.
Publish – subscribe
The Uri parameter leaks from ContentProvider API into Cursor. You can call Cursor.setNotificationUri() to specify that the Cursor will observe changes on the given Uri and propagate the notification to all ContentObservers registered with Cursor.registerContentObserver(). So when someone calls ContentResolver.notifyChange() on the same Uri, these ContentObservers will be notified of the change. This is the mechanism that powers the automatic reloading of CursorLoaders.
But what about the related Uris? Shouldn’t observers of /foo Uri be notified when the /foo/1 is updated? In case of standard Cursors that’s exactly what happens, because the observers registered in AbstractCursor base class use true as notifyForDescendents parameter. But if your specific use case requires observing only single specific Uri, you can call contentResolver.registerContentObserver(uri, false, observer).
Semantics
Content Uri semantics for querying content, i.e. how the Uri path affects the query, were already described in “Content Uris 101” section above. Semantics for other actions are not explicitly specified anywhere in the Android documentation, but again I/O Schedule app and system ContentPoviders implement it in a common way that can be thought of as standard to be followed.
For deletes and updates the Uri path are treated the same ways as for queries – as additional selection.
For inserts, the Uri path is translated to additional ContentValues that should be inserted into database, e.g. insert on /foo/42/bar create new bar record with supplied ContentValues and with foo_id (or similar foreign key field) set to 42.
Issue #1 – many to many
The described mechanics work well for one-to-many relations, but there is a problem with entities in many-to-many relations. Let’s use sessions and tags from Google I/O Schedule app as an example. Each session can be tagged with mutliple tags, and many sessions can be tagged with the same tag.
The semantics of querying /sessions/*/tags or /tags/*/sessions are OK. The first one should return all tags of a given session and the second one should yield the list of sessions tagged with a given tag. But on which Uri should you insert a new link between existing tag and existing session?
Usually many-to-many relationships are modeled with linking table, in this case “sessions_tags”. But you cannot really pass the related tag and session in Uri path: /sessions/*/tags/*/sessions_tags or similar Uris look weird. One option is to put it directly in ContentValues, but this means that this entities will be created in a different way than all the other entities in one-to-many relations. Another option is use query parameters, i.e. insert on /sessions_tags?relatedTo=/tags/*&relatedTo=/sessions/* Uri, which is ugly, but explicit.
Issue #2 – subscription vs. joins
Let’s go back to querying the /sessions/*/tags endpoint. Under the hood we’d join tags table with sessions_tags table, but most likely we’d set the Cursor’s notification Uri to /sessions/*/tags. It means that our Cursor won’t be notified of changes on /tags, /sessions_tags and descendant Uris, although it might affect the data we queried.
The only solution offered by Android SDK is calling notifyChange on insert, delete and update with multiple Uris, but there are two issues with this approach: you might end up notifying half of your endpoints for every small change, forcing way to many content reloads; it’s error prone, because changing one endpoint might require manual changes of many different endpoints.
What you really need for such cases are multiple notification Uris on Cursor, alas, that’s not possible with regular Cursors implementations.
One of the first section of Android API Guides is the description of different app compontents. New developers can read about Activities, which map directly to app UI, about Services, which perform background tasks, about BroadcastReceivers, which let’s your app react to different system events, etc. At some point they read about ContentProvider and they think:
Why would I want to use it?
Android documentation give two reasons: when you want to share data with other applications; or when you want to integrate with search framework. I’d say these use cases do not apply to most of the Android applications out there, but there are other resasons for using ContentProviders.
Database handle management
Let’s say you don’t use ContentProvider, but you want to use the SQLite database to store your data. Most likely you’ll end up with the SQLiteOpenHelper singleton in your Application object with some helper methods. Easy to code, but it’s really reimplementation of Context.getContentResolver().
Encapsulation
If you go with the solution described above, you’ll operate directly on the SQLiteOpenHelper or SQLiteDatabase objects and if you’re not careful, this implementation detail will leak across your application. Ideally you should create an abstraction around it, but then you’ll end up with something like ContentProvider anyways.
When in Rome, do as the Romans do
The ContentProvider API is leaked throughout the Android SDK. Whether it’s good or bad thing is a topic for another blog post, but the facts stay the same. If you decide not to use the ContentProvider, you forego publish-subscribe mechanism provided by CursorLoaders (tl;dr: you can set up automatic reload of data on the UI when the data is updated), SyncAdapter framework with built-in throttling, etc. You can implement all of this on your own, but you probably should focus on your business logic and UX instead of rewriting Android SDK.
IPC
As in “Inter-process communication”. I haven’t seen this point raised in any ContentProvider discussions, but the ContentProvider can be moved to separate process (if you don’t do some smelly things like accessing singletons) or accessed from any other processes in your application. And why would you want to do this?
If you don’t do some brain-dead stupid things, the biggest source of animation jank in your application is garbage collection pauses. This problem is partially solved by GC improvements in ART in Android L, but let’s face it – I don’t expect will be minSdkVersion=20 before the end of 2016. Until then we need another solution.
Since GC is performed per-process, one thing you can do is moving your memory intensive operations – like web API access and JSON parsing – to another process. But if you want to access your database from another process you can’t use SQLiteOpenHelper singleton. You’ll have to access it through some IPC mechanism. ContentProvider gives you this for free.
Summary
There are more to ContentProviders than you can see in the official documentation or top 5 hits on Google search. Actually, this is the first post in the upcoming series of posts in which I’ll describe some other aspects of ContentProvider implementation like content Uris design, thread safety, ContentProvider API deficiencies, documentation samples suckage and some solutions that can make implementing ContentProviders less painful. Stay tuned!
Three weeks ago I wrote a proguard-please plugin. I was super excited by this project because:
It was a Gradle plugin, something I wanted to play with for quite some time
It was written in Groovy, a language I wanted to play with for quite some time
It solved a real issue with ProGuard configuration, which was pissing me off for quite some time
On configuring ProGuard
If you’re not familiar with ProGuard, here’s the basic info: it’s a program which prunes the unused code from your compiled Java program. It can also do other stuff like optimization or code obfuscation and repackaging to make the reverse engineering harder. Sounds good? The catch is that ProGuard sometimes cuts out or obfuscates too much code, which usually breaks the app, especially if you rely on reflection. The trick is to configure it correctly for each library you use, but it’s not a trivial task.
The general idea for this plugin was to resolve the dependencies of your Android application and try to find the ProGuard configuration for every one of them. Of course the ProGuard config will not magically appear: the idea was to have a repository of configurations developed by the community.
On Gradle
First part of the project went really smooth, thanks to the amazing documentation. I didn’t need to do any fancy stuff, so I was able to configure the basic scaffolding in no time at all. Docs for android gradle plugin are pretty much non-existent, but using the imported sources and android-apt plugin by Hugo Visser as a base for Android related tasks I was able to get my plugin up and running.
On Groovy
I saw the Groovy for the first time at KrakDroid conference, when Wojciech Erbetowski converted boring JUnit tests into RoboSpock goodness. It looked nice, but when I started coding in Groovy, my love for this language faded.
There are lot of things I take for granted as a Java developer: amazing IDE, instant feedback when I screw something up and documentation for the code under my cursor at my fingertips. Maybe switching to Groovy, Ruby or Python requires some mindset change I haven’t fully embraced, but I simply cannot imagine why would I switch to the language that effectively forces me to write my code in Notepad™.
I think the main problem I have with Groovy stems for the fact that there are some APIs that wouldn’t typecheck in regular Java. Consider this code:
12345
if(!project.android["productFlavors"].isEmpty()){thrownewProjectConfigurationException("The build flavors are not supported yet",null)}defobfuscatedVariants=project.android["applicationVariants"].findAll{v->v.obfuscation!=null}
It’s a classic type of what I call “string typing”: depending on the key used in project.android[] access you get collection of objects of completely different type. As a consequence, the IDE cannot provide you with autocompletion or documentation for the collection contents.
Another example is the public API of Grgit library. Theoretically you can call Grgit.clone(...), but there is no such method as clone in Grgit class, instead you have this code:
I don’t see what’s wrong with the good ol’ static method and what do you achieve by using methodMissing (besides confusing the IDE and breaking autocomplete/javadocs). Maybe I’m just grupy old fart with brain eroded by too long exposure to Java, but Groovy is definitely not a language for me. I’ll put up with it if I ever want to write another gradle plugin, but it’s not going to be my go to language.
What’s up with the blog title?
Few hours after publishing my project, another solution for ProGuard configuration appeared. It turns out, if you use gradle to build your library, you can configure consumerProguardFiles property to include in your aar package a ProGuard configuration that should be used by the users of your library. The logical next step is creating the library project containing only the ProGuard configuration for the most popular libraries out there. And that’s exactly what squadleader project is.
It’s not as flexible solution as my proguard-please plugin, but it’s much simpler, much easier to contribute to and the net effect is the same. In this light I chose to put my project on hold and redirect developers to squadleader page.
Despite of that, I’m glad I worked on this project. I’m very excited by the fact that you can easily build an useful tool that’s incredibly easy to use. Using gradle for a new build system was a great call.
If you’re programming for the same platform for some time, you have probably developed some habits. You do some stuff in a particular way, because you’ve always done it this way. It might be a good thing if you know all pros and cons of your solution, because your code will be consistent and you don’t waste time rethinking the same things over and over again. On the other hand it is a good practice to question this established ways of doing things from time to time – maybe you’ve missed something when you thought about this last time or some of your arguments are no longer valid.
For me one of such things was the Serializable vs. Parcelable conundrum. A long time ago I read somewhere that Serializable is much slower than Parcelable and it shouldn’t be used for large objects, but it’s fast enough for passing simple POJOs between Fragments and Activities with Intent or arguments Bundle. While this is still a generally good advice, I realized I don’t know how much faster the Parcelable is. Are we looking at 10µs vs. 15µs or 10µs vs. 10ms?
I’m too lazy to write a benchmark myself, but I found a decent article. Tl;dr: on modern hardware (Nexus 4) serializing a simple data structure takes about 2ms and using Parcelable is about 10 times faster.
Another hit on Google was a reddit thread for this article. I found there an interesting comment by +Jake Wharton:
Serializable is like a tattoo. You are committing to a class name, package, and field structure forever. The only way to “remove” it is epic deserialization hacks.
Yes using it in an Intent isn’t much harm, but if you use serialization there’s a potential for crashing your app. They upgrade, hit your icon on the launcher, and Android tries to restore the previous Intent for where they were at in your app. You changed the object so deserialization fails and the app crashes. Not a good upgrade experience. Granted this is rare, but if you ever persist something to disk like this it can leave you in an extremely bad place.
There are two inaccuracies in the comment above. First, the problem will happen only if the app is started from the recet apps list, not from the launcher icon. Second, the problem is not limited to Serializable extras: Parcelable might read the byte stream originally written from a different structure (in this situation crash is a best case scenario), some extras might be missing, some might hold wrong type of data.
Can you prevent this issue? I don’t think so, at least not without some sophisticated validation of Intent extras. Considering that this issue is very rare and it goes away after starting the faulty app from somewhere else than recent apps list I don’t think you should spend any time trying to fix it, but it’s good to know about it, as it might explain some WTF crash reports coming your way.
Here are my thoughts after watching the keynote and few Android related sessions.
Highlights
Android One
This might be a huge, not only because it means expanding the potential user base for your apps. The most important thing is that all these new devices will run the latest Android and software updates will be provided by Google. If this kind of support becomes standard, we might be able to use minSdkVersion=20 pretty soon.
ART
The Dalvik was decomissioned, the new runtime is the only runtime. I do hope this means that the 64k method limit is no longer a problem and there are no technical roadblocks for Java 8 support. Maybe this questions were answersed during The ART runtime session, unfortunately there was no live stream of it.
Edit: the video from the session is available. The GC improvements and performance boosts are amazing, but if I understand everything correctly the ART still uses dex bytecode underneath, so all Dalvik limitations are still in place. Bad Google.
I got the feeling that he’s the only Google employee who acknowledges that there are serious issues with developing on Android. Great answers about unit tests and robolectric support, good answer about Scala support.
Dunno what to make of it
RecyclerView
ListViews are far from perfect. I know, because in our codebase we have few workarounds for the issues or poor APIs. It’s good that something more flexible is available, it’s great that it’s a part of support library, but some parts of the RecyclerView API look incredibly complex.
Unlock bypass with Wear device
Call me paranoid, but this feature means that if I get mugged, I’m totally screwed. Someone gets access to my email, and through that he gets access to every piece of my data on the web and my digital idendity. Thanks, I’ll pass.
On the other hand there are users who do not use pin or pattern on the lockscreens. For these people, this feature is a significant security improvement.
Lowlights
Always running, big-ass TVs
During keynote one speaker mentioned that in average household the TV is on for 5 hours every day and suggested that for the other 19 hours it can be used as a digital canvas for your content. I’m not sure if encouraging people to keep the huge, power hungry device all the time to display nice pictures is very thoughtful and enviromentally aware.
Fireside chat
There were some über lame questions from the audience, but that’s expected when questions are not moderated. However there were also über lame answers for valid questions, and there is no excuse for it.
The very first question, about Java 8 support, was answered with smirks and a slimy answer from Chet Haase. Dear Google, after WWDC the Java 8 support is no longer a huge news, so if you’re saving it for the future, don’t bother. And if there are any issues with Java 8 support – legal, technical, whatever – just let the developers know.
As madeupstatistics.com report, 95% posts about git can be divided into three types:
Whining about rebases, because “git history is a bunch of lies”.
Right, because everyone needs to see your “fixed typo” mistakes and early API design blunders.
Whining about rebases, because you should document the “roads not taken”, not obliterate them.
This argument is actually pretty good, but from my experience these not taken roads, dead ends and detours do not tell the full story either. VCS is not the right tool for this.
Whining about crappy CLI command names.
It’s hard to defend some choices, but here’s the thing: you need to memorize maybe a dozen commands and in return you get the most powerful VCS tool you can get today. So toughen up princess, stop whining and learn them.
So today I was pleasantly surprised when I found today actually a good blog post about git UI. Go ahead and read it. While I do not agree with everything OP wrote, he got two things right: git model and git log --graph improvements.
Git Mental Model
People do not need to know that there are blobs, sha checksum calculated from whatnot and so one. What I say to every git newcomer is this: commits are connected with parent commits, and branches, tags, HEAD, etc. are all just pointers to commits. Then you just need to figure out that git commit doesn’t do any magic, it just adds commit and moves HEAD and current branch pointers.
Commits Graph Representation
Every git workflow description contain a beautiful, clear diagram explaining where commits are added and merged – this is a good example. Then you start using this workflow and after two weeks your git log --graph --all output looks like a failed knitting experiment. The difference is that the diagrams keep the commits from a single branch aligned in a column, and git log tries to reduce the space taken by graph, which mixes multiple branches in a single column.
I’m not sure if it’s doable with current git data model though – the commits do not contain any information about the branch. I think the branch name could be derived from the current branches and merge commits messages, but I’m sure it won’t work for 100% of cases. For these edge cases it would be great to allow users to manually select the correct branch, but this means the branch information would have to be kept outside of commits, but inside git. Tricky stuff.
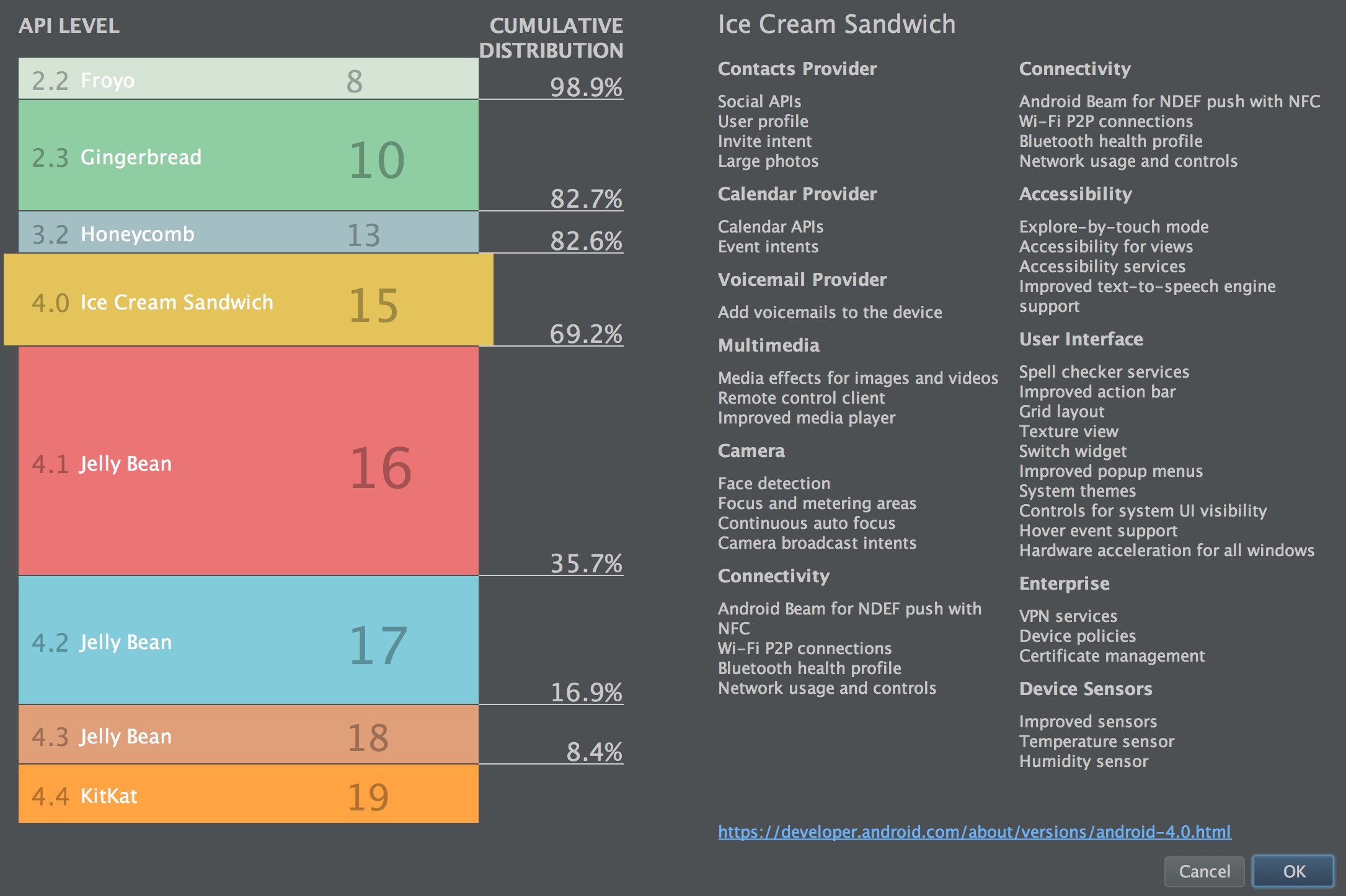
A year ago Jeff Gilfelt was giving away minSdkVersion=14 stickers, promoting the idea of dumping the support for Gingerbread and Honeycomb. What seemed radical one year ago, today is a widely accepted. The minSdkVersion in new project wizard in latest Android Studio release is by default set to 15. On the same screen you can click the “help me choose” hyperlink, which shows this screen:
The percentages are consistent with data from developer.android.com dashboards, but I’d say they are skewed towards old Android versions. Base CRM app I’m working on has only 3.7% active users on devices with api level < 15 (compared to 17.4% from official Google dashboards). Moreover, if you look only at the new users, the Froyo, GingerBread and Honeycomb is used only by 1%. In this light, supporting pre-API15 devices is a criminal waste, and starting new projects with minSdkVersion lower than 15 a criminal idiocy.
For me, as a delevoper, the minSdkVersion=14 is a breakthrough, mostly because of Holo theme available everywhere. I no longer have to worry about HTC rounded green buttons and such when creating custom views – I only have to make them look good with a single theme. Theoretically one could have used HoloEverywhere lib, but it’s not a drop-in replacement. First you have to switch to using their Views instead of native ones and adjusting any external UI library to use them as well.
I looked through the Android changelogs wondering what could be the next version on minSdkVersion stickers. The next step is a small bump to JellyBean (API level 16), which gives us access to actions in system notifications and condensed and light Roboto font variants. Official statictics state that Ice Cream Sandwich is used by 12.3% of users, but this number is much higher than the one from Base statistics – 5.87%. I expect dropping support for ICS this year.
But then? I don’t see anything as groundbreaking as dropping Gingerbread. I don’t even see anything with more impact than dropping ICS. Theoretically API level 17 gives access to nested fragments, but I think you should be using support-v4 classes anyways (and if you check the Google I/O 2014 app sources, Google developers seem to think so too). Maybe there’s something I missed or something crucial for specific use cases – do let me know if there’s anything in API levels 17-19 you wish you could use already.
Google I/O is coming though, and some things indicate we might see Android 5.0 (or at least Android 4.5). Maybe this Android “L” version will be another breakthrough in development? My personal wish is a new runtime without ridiculous 64k method limit. Of course this opens a lot of other possibilities. Maybe support for Java 8? Or first-class support for other JVM languages? We’ll see…
I usually tend to write about certain gotchas and weird Android issues, so if you expect yet another rant, I have a surprise for you – today, I’m going to write about a piece of code I’m very fond of.
When I first saw this API I was a bit worried about performance, because this code is supposed to be used in Comparators, which are executed multiple times during Collection sorting, and it looks like it could allocate a lot of objects. So I looked at the source code and I was enlightened.
ComparisonChain is an abstract class with few versions of compare method returning ComparisonChain object:
To get the result of comparison you call another abstract method:
1
publicabstractintresult();
The trick is, there are only two implementations and three instances of ComparisonChain: anonymous ACTIVE, and LESS and GREATER instances of InactiveComparisonChain.
ACTIVE instance is the one you get from ComparisonChain.start() call. Various compare methods in ACTIVE instance perform comparison on supplied arguments, and depending on result return ACTIVE, LESS or GREATER object. Calling result on ACTIVE ComparisonChain yields 0.
InactiveComparisonChain’s instances – LESS and GREATER – do not perform any comparisons and return themselves – if you got this object, it means that earlier comparison already established the result. The role of this object is just to forward result call to appropriate instance. LESS.result() returns -1 and GREATER.result() +1.
The whole class is elegant, provide beautiful API for a common task and the implementation is very efficient. The world needs more code like this.