Meeting two out of three goals and some open source bonus ain’t that bad. The gloating part is done, let’s move to the wishful thinking part, a.k.a. goals for 2014:
Keep giving the talks. I find that preparing the presentation forces me to do thorough investigation of the topic, question all my assumptions and prepare answers for potential questions. This is probably the best way to learn about something, and as a bonus you’re sharing that knowledge afterwards.
Blog more. This year for each post I wrote I have added at least one more topic to my blog todo list. The resolution for this year is clearing this backlog and generating at least 25k views. BTW: when I started this blog I feared that I won’t have enough content to write regularly. Bollocks.
Publish at least one app on Google Play.
Keep working on the libraries I have published this year. It might not be a perfect metric of how useful to others my work turns out to be, but I’d like to accumulate 200 Github stars total on the projects I authored or co-authored.
The only thing left to be done is to wish you a happy New Year!
I faced this dilemma recently, when I was preparing first release of Cerberus utility for Android. On one hand, in Cerberus I used a tiny subset of Guava features which can be trivially rewritten in vanilla Java in 15 minutes, so maybe I should not force Guava down peoples throat? On the other hand I’m a hugefan of Guava and I think you should definitely use it in anything more complicated than “Hello, world!” tutorial, because it either reduces a boilerplate or replaces your handrolled utilities with better, faster and more thoroughly tested implementations.
The “this library bloats my apk” argument is moot, because you can easily set up the ProGuard configuration which only strips the unused code, without doing any expensive optimizations. It’s a good idea, because the dex input will be smaller, which speeds up the build and the apk will be smaller, which reduces time required to upload and install the app on the device.
I found the problem though, which is a bit harder to solve. Modern versions of Guava use some Java 1.6 APIs, which are available from API level 9, so when you try to use it on Android 2.2 (API level 8), you’ll get the NoSuchMethodException or some other unpleasant runtime error (side note: position #233 on my TODO list was a jar analyzer which finds this problem). On Android 2.2 you’re stuck with Guava 13.0.1.
This extends also to Guava as a library dependency. If one library supports Android 2.2 and older, it forces old version of Guava as dependency. And if another library depends on more recent version of Guava, you’re basically screwed.
One conclusion you can draw from this blog post is that you shouldn’t use Guava in your open source libraries to prevent dependency hell, but that’s spilling the baby with the bathwater. The problem is not Guava or any other library, the problem are Java 1.6 methods missing from Android API level 8! The statistics from Google indicates that Froyo is used by 1.6%, in case of Base CRM user base it’s only 0.2%. So more reasonable course of action is finally bumping minSdkVersion to 10 (or even 14), both for your applications and all the libraries.
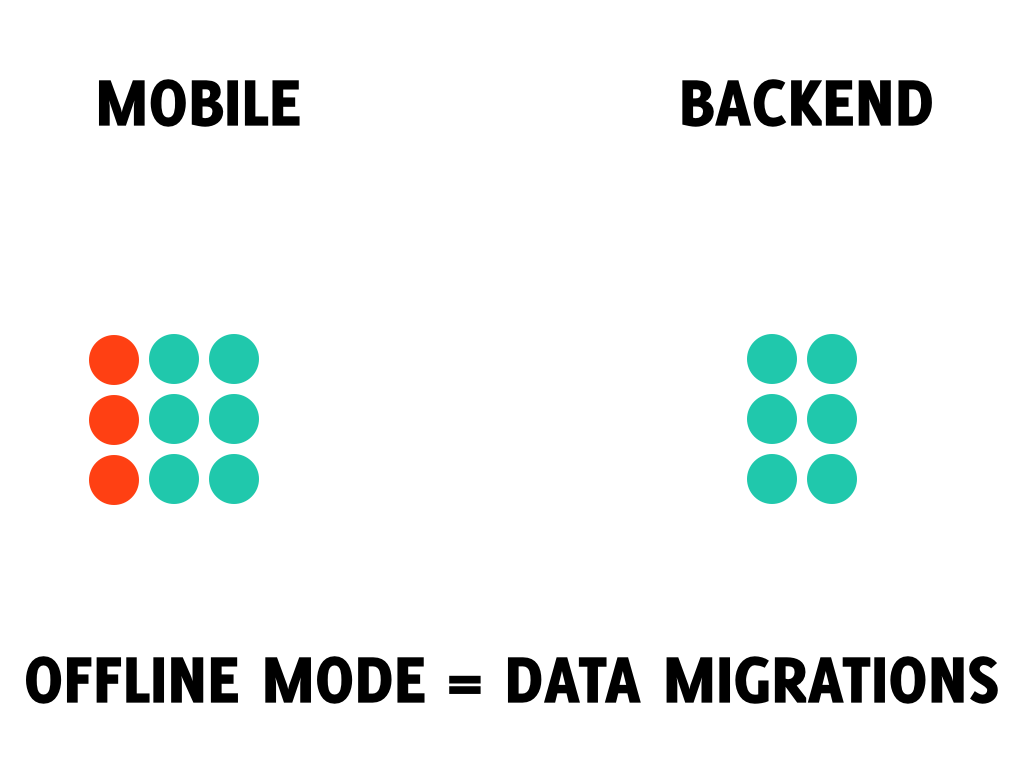
This year I gave a talk on Krakdroid conference about offline mode in Android apps. By offline mode I mean implementing the app such way that the network availability is completely transparent to the end users. The high level implementation idea is to decouple the operations changing the data from sending these changes through unreliable network by saving the changes in local database and sending them at convinient moment. We have encountered two major problems when we implemented this behavior in Base CRM: data migrations and identifying entities. This blog post describes the first issue.
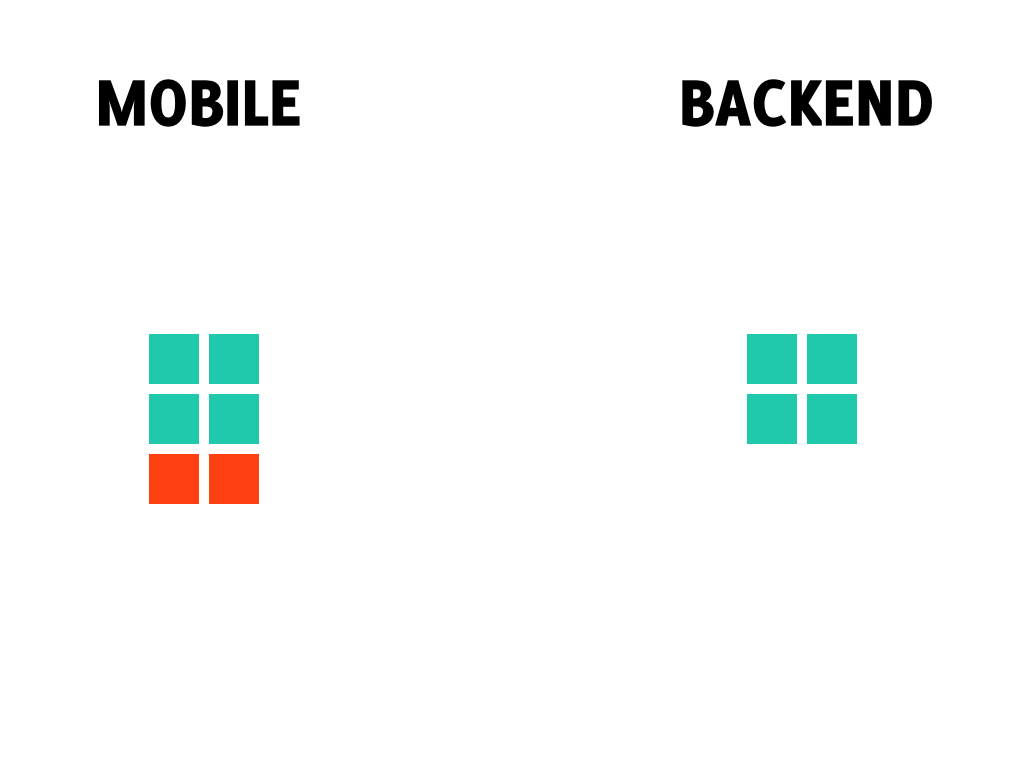
It might not be obvious why do you need the data migrations, so let’s clear this out. Let’s say on your mobile you have some data synced with backend (green squares on left and right) and some unsynced data created locally on mobile (red squares on the left).
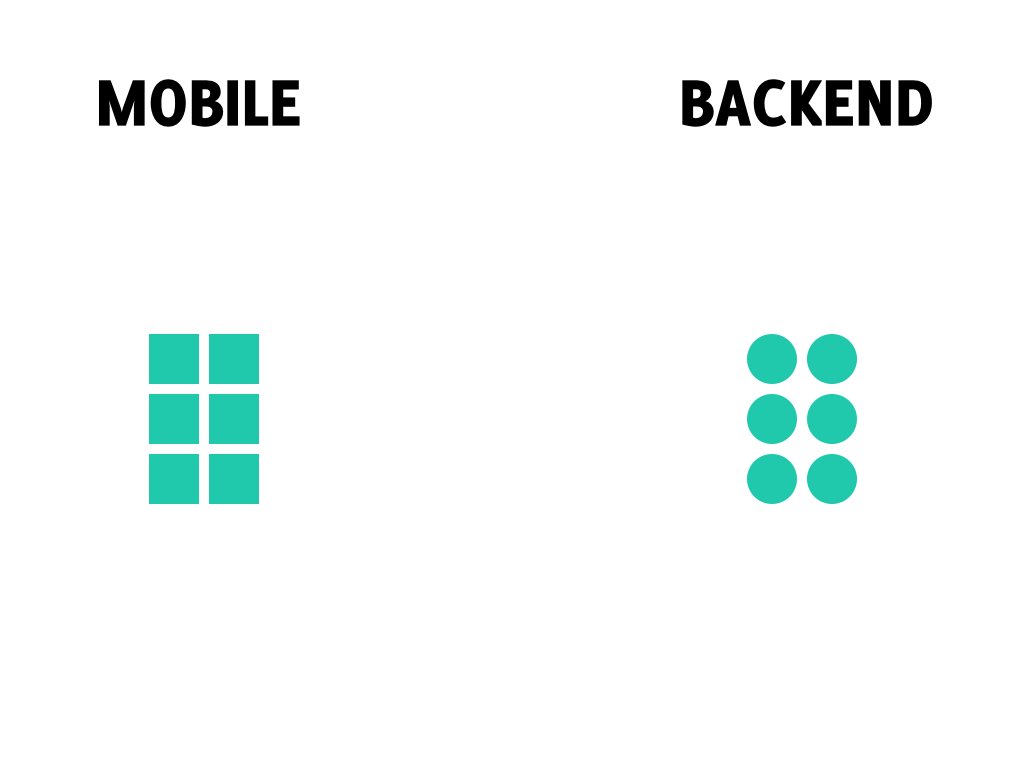
Now let’s say that we introduce new functionality to our app, which changes the schema of our data models (the squares on the backend side are changed to circles).
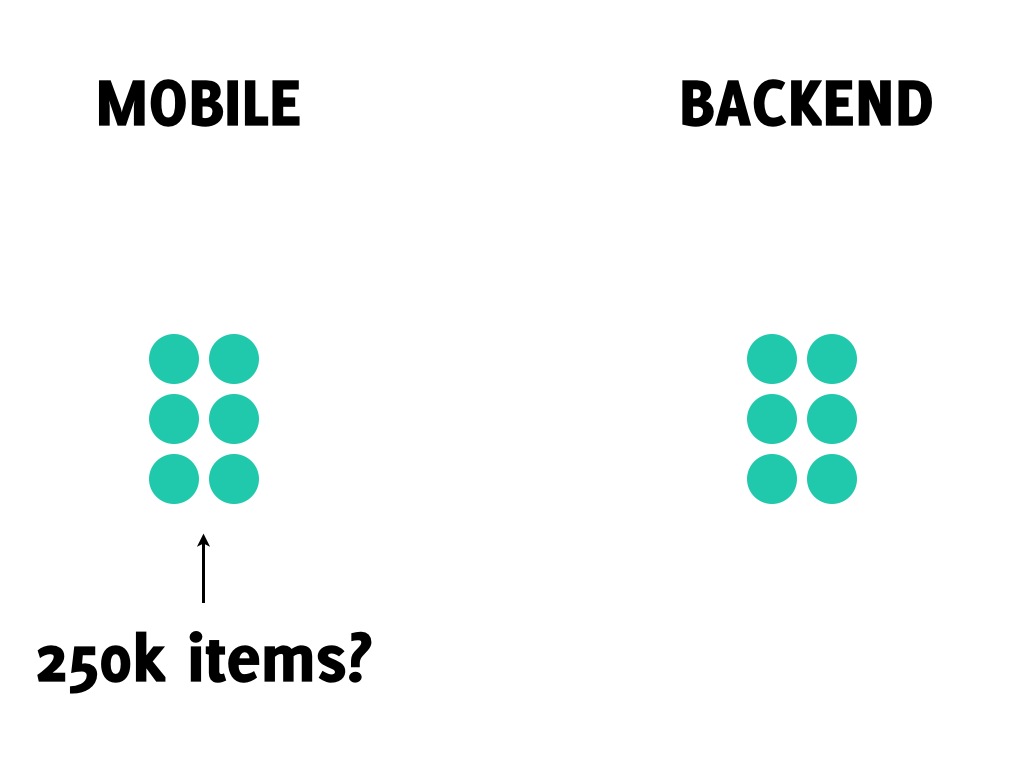
The schema of the local database have to be changed as well. The naive way of handling this situation is dropping old database with old schema, creating new one with new schema and resyncing all the data from backend, but there are two issues with this approach: if there is a lot of data the resyncing might take a while, which negates the most important advantage of offline mode – that the app is fully functional all the time.
More serious issue is that dropping the old database means that the unsynced data will be dropped along with it.
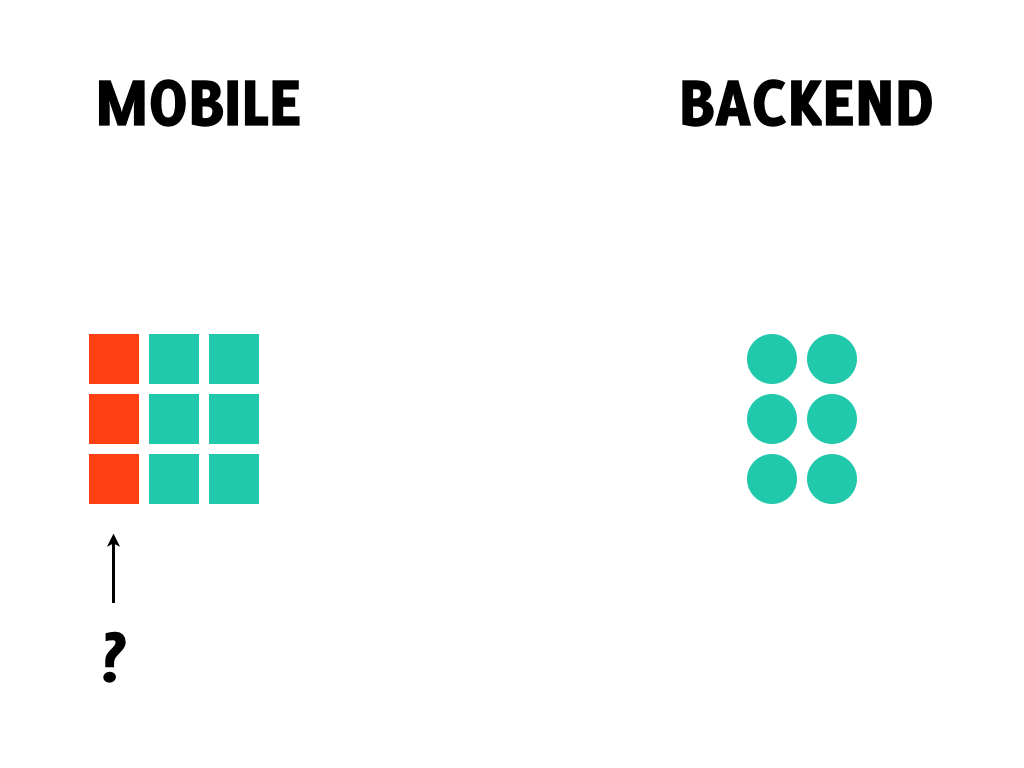
The only way to provide the optimal user experience is to perform schema migrations locally for both synced and unsynced data:
Migrating the data doesn’t sound like a challenging thing to code, but the combination of obscure SQLite and Android issues complicates the matter. Without proper tools it’s quite easy to make your code unmaintainable in the long run. I’ll describe this issues and our solutions in the further posts.
At the beginning of the December I had an opportunity to gave a talk on a Krakdroid conference. The organizers outdid themselves this year, the venue, other speakers and the overall event atmosphere was amazing. Definitely a place to be at if you’re in Krakow at the end of the year.
This year I talked about the offline mode in Android apps. The talk was 30% sales pitch, 10% shameless plug and 60% describing the pitfalls one can fall into when implementing offline mode. I’m going to describe two major problems with offline mode in details on my blog and here are the slides:
Protip on giving a public speech – take a sip of water every 2-3 slides, especially if you’re not feeling well and you have a sore throat.
I got an atrocious headache in the afternoon and went home, so I didn’t see all the talks, but I’ve seen the rare thing – a succesful live coding – by +Wojtek Erbetowski who presented the RoboSpock testing framework and incrementally turned a meh-Java code into concise Groove goodness. +Maciej Górski did the maps framework overview, and although he’s the author of excellent Android Maps Extensions he managed to be surprisingly objective. The first talk by +Wojtek Kaliciński triggered an internal discussion and Base about reducing the support for old Android versions. It won’t happen overnight, but at least we’ve moved from the dangerous “c'mon, it’s not that hard to support Froyo” mindtrack. I’ll definitely write more about this.
To summarise, it was a great event. I’ve learned a lot, I’ve met some interesting people and I gave another talk, which completes one of the goals I set myself up for 2013. Good stuff.
tl;dr: don’t left join on view, or you gonna have a bad time.
I have investigated a performance issue of the db in Android app today. The symptoms looked like a classic case of the missing index: the performance degraded with adding more data to certain tables. However, the quick check of sqlite_master table and looking at some EXPLAIN QUERY PLAN queries indicated that everything is properly indexed (which is not very surprising, given that we use android-autoindexer).
I started dumping the explain query plans for every query and it turned out that some queries perform multiple table scans instead of single scan of main table + indexed searches for joined tables. It means that the indices were in place, but they weren’t used.
The common denominator of these queries was joining with a view. Here’s the simplest schema which demonstrates the issue:
1234567891011121314151617
sqlite> create table x (id integer);
sqlite> create table y (id integer, x_id integer);
sqlite> explain query plan select * from x left join y on x.id = x_id;
selectid order from detail
---------- ---------- ---------- ----------------------------------------------------------------
0 0 0 SCAN TABLE x (~1000000 rows)
0 1 1 SEARCH TABLE y USING AUTOMATIC COVERING INDEX (x_id=?) (~7 rows)
sqlite> create view yyy as select * from y;
sqlite> explain query plan select * from x left join yyy on x.id = x_id;
selectid order from detail
---------- ---------- ---------- -------------------------------------------------------------------
1 0 0 SCAN TABLE y (~1000000 rows)
0 0 0 SCAN TABLE x (~1000000 rows)
0 1 1 SEARCH SUBQUERY 1 USING AUTOMATIC COVERING INDEX (x_id=?) (~7 rows)
Of course this behaviour is documented in the SQLite Query Planner overview (point 3 of the Subquery flattening paragraph), and I even remember reading this docs few times, but I guess something like this has to bite me in the ass before I memorize it.
Everything works fine if you copypaste the views selection in place of the joined view, which makes me a sad panda, because I wish SQLite could do this for me. On the other hand it’s a very simple workaround for this issue, and, with a right library, the code might even be manageable.
The SQL injection through query parameters is the common security issue of any system using SQL database. Android is no different than any other system, so if you’re using SQLite database in your Android app, you should always sanitize the database inputs.
If you are also using an exported ContentProvider, you need to take care of one more vector of attack: the projection parameter of the queries. Just like SQLiteDatabase, the ContentProvider allows the users to specify which columns they want to retrieve. It makes sense, because it reduces the amount of data fetched, which might improve performance and reduce the RAM footprint of your app. Unlike the SQLiteDatabase, the ContentProvider might be exported, which means that the external applications can query the data from it requesting an arbitrary projection, which are then turned into raw SQL queries. For example:
123
'Bobby Tables was here';DROPTABLEStudents;--*FROMsqlite_master;--*FROMnon_public_table_I_found_out_about_using_previous_query;--
Basically it means that if you exposed a single uri without sanitizing the projection, you have exposed your entire db.
So how do you sanitize your projections? I’ve given it some thought and it seems that the only sensible thing to do is allowing only subsets of predefined set of columns.
You cannot allow any expression, because you’d allow any expressions, including SELECTs from other tables and allowing certain expressions is not a trivial task.
You shouldn’t ignore the provided projection and return all columns, because one of the benefits of using projections is limiting the amount of data retrieved from database. Besides, certain widely used Google application ignores the existence of Cursor.getColumnIndex method and assumes that the columns will be returned in the same order they were specified in projection. The other app won’t work correctly, and the users will probably blame you.
I’ve run into a funny little problem when creating custom drawables recently – some of the lines were crisp and some were blurred:
After few debug iterations I was able to narrow down the difference to the shapes drawn using the Canvas.drawRoundRect and Canvas.drawPath. The former looked much crispier. I’ve dug down to Skia classes and it turns out that they reach the same drawing function through slightly different code paths and I guess at some point some rounding is applied at one of them, but I haven’t verified this.
The minimal example which demonstrates the issue are two solid XML shape drawables (which are parsed into GradientDrawables), one with radius defined in radius attribute, the other one with four radii defined (can be the same).
Besides satisfying my idle curiosity and honing my AOSP code diving skills, I have learned something useful: do not mix paths and round rects on Canvas and use Path.addRoundRect with radii array when your path contains other curved shapes.
We’re starting to find more and more interesting use cases for Thneed in Base CRM codebase. The first release using it, and fewotherlibrarieswerecentlydeveloped, was released just before the Halloween and we haven’t registered any critical issues related to it. All in all, the results look very promising. I won’t recommend using Thneed in your production builds yet, but I urge you to star the project on Github and watch its progress.
The Thneed was created as an answer to some issues we faced when developing and maintaining Base CRM, and this fact is sometimes reflected by the API. The example of this is something we internally called PolyModels.
Let’s start with a scenario, where we have a some objects and we’d like to add notes to. It’s a classic one-to-many relationship, which I’d model with a foreign key in notes table:
Now let’s introduce another type of objects, which also can have notes attached to it. We have few options now. The simplest thing to do is to keep these notes in a completely separate table:
The issue with this solution is that we have two separate schemas that need to be updated in parallel, and in 95% of cases would be exactly the same. Another approach is making the objects which contain notes sort of inherit a base class:
These two solutions work perfectly in the “give me all notes for object X” scenario, but it gets ugly if you want to display a single note with the simple “Associated with object X” info. In this case you have to query every model which can contain notes, to see if this particular association references the objects from this model. On top of that, the Noteable table approach requires some additional work to create the entry in
You can always have a several mutually exclusive foreing keys in your notes:
But this solution doesn’t really scale well as the number of the models which can contain notes increases. Also, your DBAs will love you if you go this way.
The solution to this problem we used in Base was to have two columns in Notes table: one holding the type of the “noteable” object, i.e. and the other for the id of this object:
The glaring issue with this approach is losing the consistency guarantee – no database I know of support this kind of foreign keys. But when you have SOA on the backend and the notes are stored in a separate database than the noteable objects, this is not your top concern. On mobile apps, even though we have a single database, we use the same structure, because all the other have some implementation issues and worse performance characteristics.
I’m not a db expert, and I haven’t found any discussion of similar cases, which means that a) we’re doing something very wrong or b) we have just very specific requirements. Let me know if it’s a former case.
I needed to model this relationships in Thneed, which tured out to be quite tricky, but that’s the topic for another blog post.
I gave the talk at the Mobilization 2013 conference this weekend. I have presented few libraries created at Base CRM to make the data model maintainable. Here are the slides:
Besides giving the talk, I have attended few other very interesting talks: +Wojtek Erbetowski has shown the way they test Android apps at Polidea using RoboSpock; +Mateusz Grzechociński introduced Android devs to new build system and shared an awesome gradle protip: use —daemon command line parameter to shave off few seconds from gradle startup. +Mateusz Herych described the Dagger basics and warned about few pitfalls. Mieszko Lassota described some UI blunders not only from the programming world. Finally, Krzysztof Kocel and Paweł Urban summarised the security pitfalls.
All in all, this years Mobilization conference was a great place to be at. See you there next year!
A while ago I wanted to perform a certain operation for every subsequent pair of elements in collection, i.e. for list [1, 2, 3, 4, 5] I wanted to do something with pairs [(1, 2), (2, 3), (3, 4), (4, 5)]. In Haskell that would be easy:
The problem is, I needed this stuff in my Android app, which means Java. The easiest thing to write would be obviously:
1234567
List<T>list;for(inti=1;i!=list.size();++i){Tleft=list.get(i-1);Tright=list.get(i);// do something useful}
But where’s the fun with that? Fortunately, there is Guava. It doesn’t have the zip or init functions, but it provides tool to write them yourself – the AbstractIterator. Tl;dr of the documentation: override one method returning an element or returning special marker from endOfData() method result.
The tail can be achieved simply by calling the Iterables.skip:
1234
publicstatic<T>Iterable<T>getTail(Iterable<T>iterable){Preconditions.checkArgument(iterable.iterator().hasNext(),"Iterable cannot be empty");returnIterables.skip(iterable,1);}
For init you could write similar function:
1234
publicstatic<T>Iterable<T>getInit(finalIterable<T>iterable){Preconditions.checkArgument(iterable.iterator().hasNext(),"Iterable cannot be empty");returnIterables.limit(iterable,Iterables.size(iterable));}
But this will iterate through the entire iterable to count the size. We don’t need the count however, we just need to know if there is another element in the iterable. Here is more efficient solution:
12345678910111213141516171819202122
publicstatic<T>Iterable<T>getInit(finalIterable<T>iterable){Preconditions.checkArgument(iterable.iterator().hasNext(),"Iterable cannot be empty");returnnewIterable<T>(){@OverridepublicIterator<T>iterator(){finalIterator<T>iterator=iterable.iterator();returnnewAbstractIterator<T>(){@OverrideprotectedTcomputeNext(){if(iterator.hasNext()){Tt=iterator.next();if(iterator.hasNext()){returnt;}}returnendOfData();}};}};}
All methods used together look like this:
1234
List<T>list;for(Pair<T,T>zipped:zip(getInit(list),getTail(list))){// do something useful}